
Sense of Hearing in AI
A true AI system should have all five senses: sight, hearing, smell, taste, and touch as humans do. A lot of effort is being made so that AI is capable to understand signals based on these senses. Combining hearing sense or sound signals analysis along with Video will greatly improve the reliability of AI based systems. Our effort is to make AI systems capable to understand and respond to sound as humans do.
Areas and Applications
There are mainly three concepts: sound classification, speech recognition, and sound/speech generation.
- Sound Classification : Sound is a signal that has characteristics like frequency, amplitude, pitch, loudness, and time period. In preprocessing, sound is classified into these characteristics. The possbile use cases are:.
-
Surveillance System :- It is important to segregate crowd noise, individual aggressive sound and normal audio pattern in sound data and corroborate it with video analysis results to accurately detect suspicious activities.

-
Rigidness Detection :- When we knock any object like glass, wood, floor, plant, cotton etc this all generate a different type of sound. Analysis of this sound patterns helps find rigidness and strength of an object.

-
Sound Source Detection :- There are different types of sound sources, e.g Humans, environment amd machines. Detection of sound sources and classification is done.

-
Instrumental Music Classification :- There are many types of musical instruments like trumpet, piano, trombone, violin, guitar, saxophone, drum, conga, cello etc. We can classify different music sound sources.

-
Voice/Lyrics Detection :- Sound classification helps to identify audio from background noise and can differentiate lyrics and karaoke sound.
-
Audio Fingerprinting :- Audio fingerprinting gives unique identify to particular sound and protect copyrights of the sound creator. By the use of spectrogram we can detect fingerprinting of sound by using few seconds of music.

-
Childern Monitoring and Observation :- An AI generated assistant can monitor kids' sound and also analyse different types of sounds like laughing, crying, burping etc.

-
-
Speech Recognition and text conversion :Speech recognition is to identify human voice and convert it into text. Speech helps to understand commands and helps to establish a direct communication between human and system. Applications,
-
Personal Assistant :- Alexa, google assistant, siri etc divices are already available that act on voice commands within a limited scope. Personal Assitant device is more than just responding to limited voice commands so scope for enhancments in these devices and for new devices is always there.

-
-
Sound Generation :Our era is crazy about EDM(Electronic Dance Music), they want something remix with old music sound. Also it helps to manipulate sound with some minute glitch. We can manipulate our voice with some celebrity.
-
Music Generation :- There are many generative networks that helps to generate new thing either image or sound. VAE-GAN(Variational Autoencoder-Generative adversarial networks) is one of them. It used to generate new percussion, melodies and chords, on the basis of vocal sounds. Also we can create new pattern of electronic music.

-
Speech Generation :- It is NLP based concept in which we do the same as the text generation but in form of sound for example defining something similar words sentence completing.

-
Our Work -
- Pre- Process Work -
-
Sound Pre-processing – Classify sound in different characterstics.
-
Feature Extraction – We extract features first by applyling feature extraction techniques instead of using raw sample data. Mel Frequency Cepstral Coefficients (MFCC) is a commonly used feature extraction technique in speech recognition system. MFCC of a signal are a small set of features (usually about 10-20) which concisely describe the overall shape of a spectral envelope.

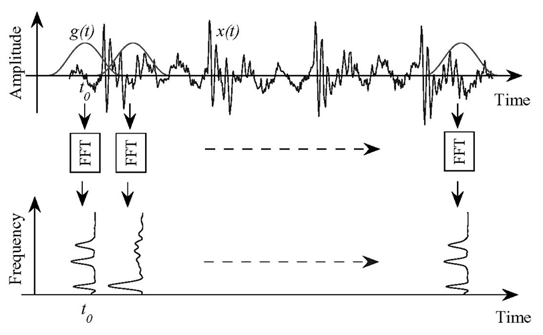
It results a MFCC feature matrix.
We can use an alternate approach by creating a spectrogram of each wave file and use this data as input. For example, If someone says “hello” and the other person says “hellllooooo” then the system must recognize the same “HELLO”.
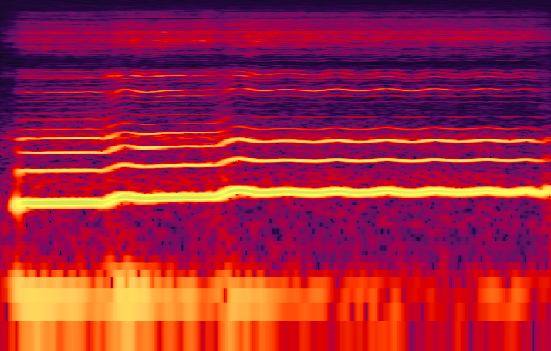
By spectrogram we get feature like frequency with respect to time and by coloring we get sound intensity. It can be used to classify sound in different ways.
-
Future Work -
As humans we can understand that Hearing is very important sense for us. After hearing a sound how fast our nervous system processes it and respond to it. And these responses are how much reliable to us. Let’s understand the concept-
- Neurolinguistic
Neurolinguistics is the study of how language is represented in the brain: that is, how and where our brains store our knowledge of the language (or languages) that we speak, understand, read, and write, what happens in our brains as we acquire that knowledge, and what happens as we use it in our everyday lives.

We can understand it by an example “All colleges and schools are under loackdown in Delhi because of...........” If this sentence is asked in front of any person in the country then definately, the answer would be corona virus according to the current situation. Here summer, pollution, riots can also be correct answer but not that much close to current situation. This is how our neurolingustic works on the basis of previous knowledge and situation. With the help of Natural Language Processing, we Intent to teach AI about part of speech so it can fill in a suitable answer to complete the sentence and enhance our system to use it’s short term memory to answer appropriately.